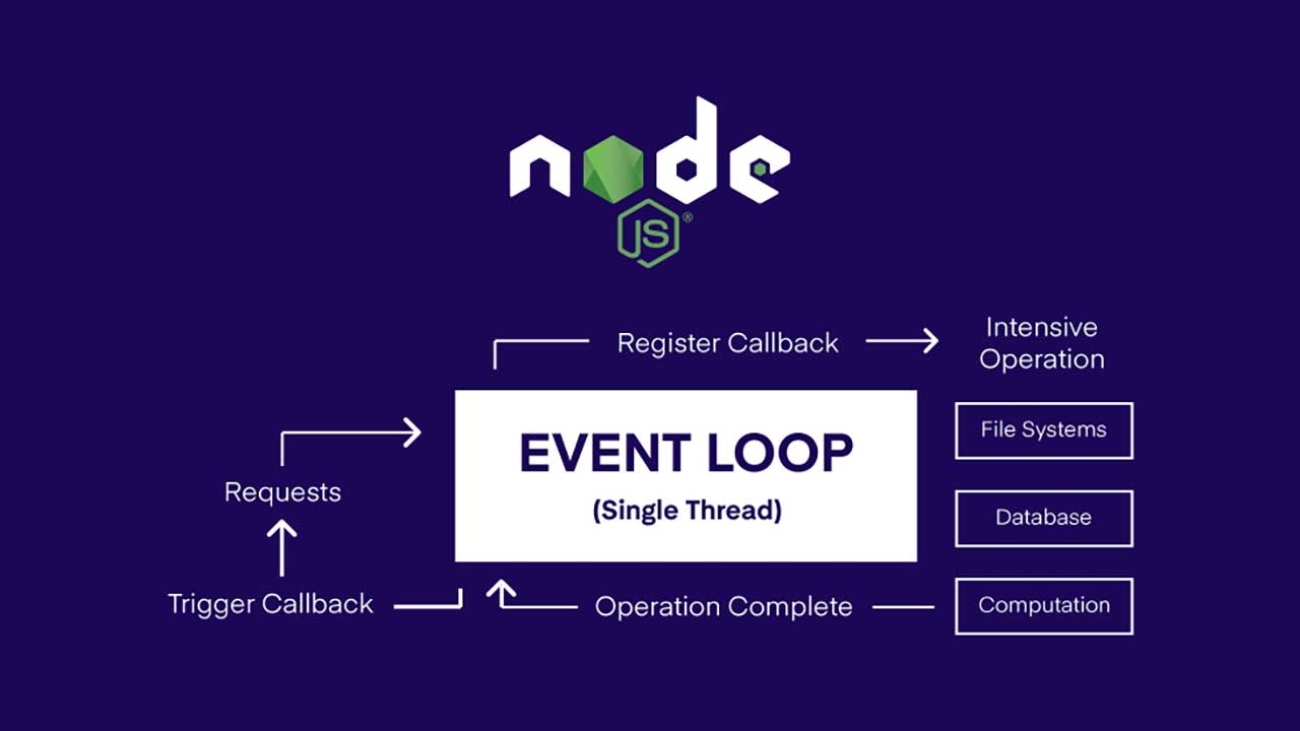
The Node.js event loop is a key feature that makes Node.js so efficient for handling concurrent requests. This blog post will explain how the event loop works and how you can use it to improve the performance of your Node.js applications.
The issue
This days backends behind websites actually don’t need to do complicated computations. Most of the programs spend their time waiting for the disk to read & write or waiting for the wire to transmit our message and send back the answer.
IO operations could be orders of magnitude slower than the data processing. Let’s take this for an example: SSD-s can have a read speed of 400-930 MB/s – at least a high-end one. Reading just one kilobyte of data would take 1.4 microseconds, but during this time a CPU clocked at 2GHz could have performed 28 000 of instruction-processing cycles.
For network communications it can be even worse, just try and ping google.com
$ ping google.com
64 bytes from 172.217.16.174: icmp_seq=0 ttl=52 time=33.017 ms
64 bytes from 172.217.16.174: icmp_seq=1 ttl=52 time=83.376 ms
64 bytes from 172.217.16.174: icmp_seq=2 ttl=52 time=26.552 ms
64 bytes from 172.217.16.174: icmp_seq=3 ttl=52 time=40.153 ms
64 bytes from 172.217.16.174: icmp_seq=4 ttl=52 time=37.291 ms
64 bytes from 172.217.16.174: icmp_seq=5 ttl=52 time=58.692 ms
64 bytes from 172.217.16.174: icmp_seq=6 ttl=52 time=45.245 ms
64 bytes from 172.217.16.174: icmp_seq=7 ttl=52 time=27.846 msCode language: JavaScript (javascript)The average latency is about 44 milliseconds. Just while waiting for a packet to make a round-trip on the wire, the previously mentioned processor can perform 88 millions of cycles.
What is the solution?
So in that case what we can do? Most of the operational systems provide some kind of an Asynchronous IO interface, which allows us to start processing data that doesn’t need the result of the communication, meanwhile the communication still goes on.
This can be achieved in several ways. Now it is mostly done by leveraging the possibilities of multithreading at the cost of extra software complexity. Let’s see an example: reading a file in Java or Python is a blocking operation. Our programs cannot do anything else while it is waiting for the network / disk communication to finish. All we can do – at least in Java – is to fire up a different thread then notify our main thread when the operation has finished.
It is tedious and complicated right! But it gets the job done. But what about Node? Well, we are surely facing some problems in Node.js – or more like V8 – is single-threaded. Our code can only run in one thread.
You might have heard that in a browser, setting setTimeout(yourFunction, 0) can sometimes fix things magically. But why does setting a timeout to 0, deferring execution by 0 milliseconds fix anything? Isn’t it the same as simply calling yourFunction immediately? Not really.
First of all, let’s take a look at the call stack, or simply, “stack”. So let’s make things simple, as we only need to understand the very basics of the call stack.
Stack
Whenever we are calling a function return address, parameters and local variables etc will be pushed to the stack. If we call another function from the currently running function, it’s contents will be pushed on top in the same manner as the previous one – with its return address.
For the sake of simplicity I will say that ‘a function is pushed’ to the top of the stack from now on, even though it is not exactly correct.
Let’s take a look!
1 function main () {
2 const hypotenuse = getLengthOfHypotenuse(3, 4)
3 console.log(hypotenuse)
4 }
5
6 function getLengthOfHypotenuse(a, b) {
7 const squareA = square(a)
8 const squareB = square(b)
9 const sumOfSquares = squareA + squareB
10 return Math.sqrt(sumOfSquares)
11 }
12
13 function square(number) {
14 return number * number
15 }
16
17 main()Code language: JavaScript (javascript)main is called first:
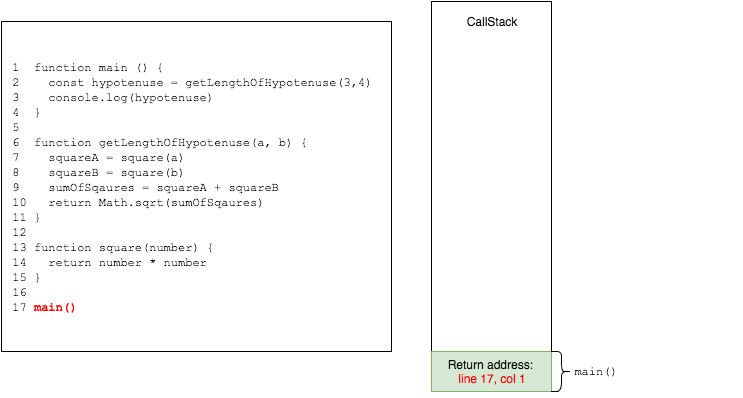
then main calls getLengthOfHypotenuse with 3 and 4 as arguments
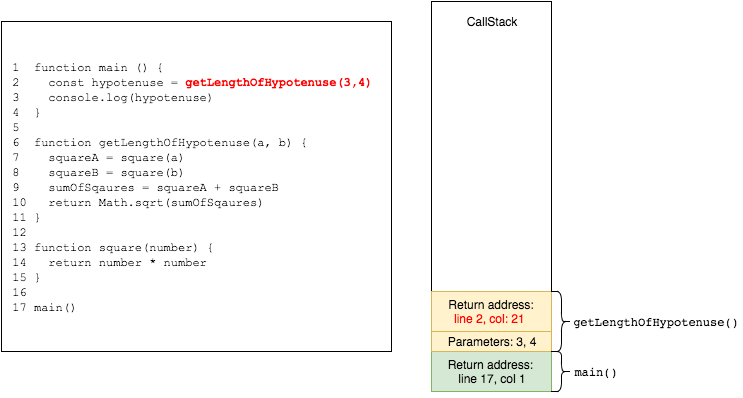
afterwards square is with the value of a
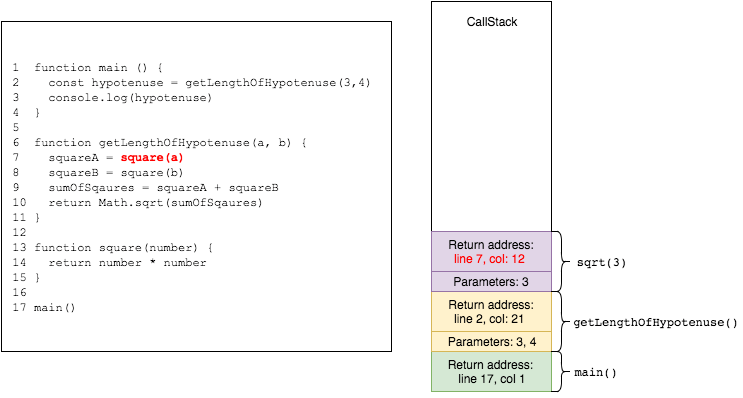
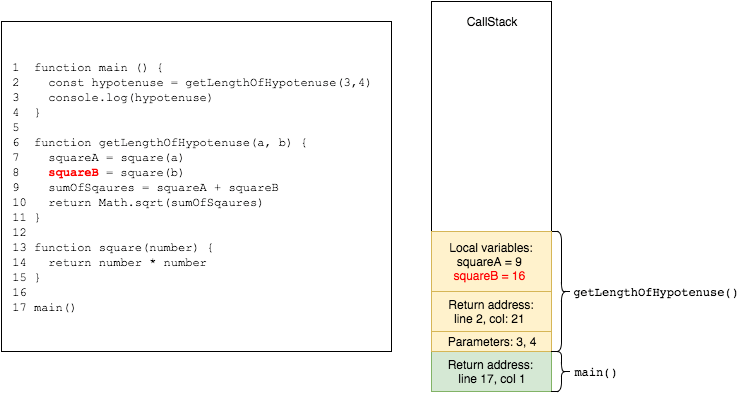
when square returns, it is popped from the stack, and its return value is assigned to squareA. squareA is added to the stack frame of getLengthOfHypotenuse
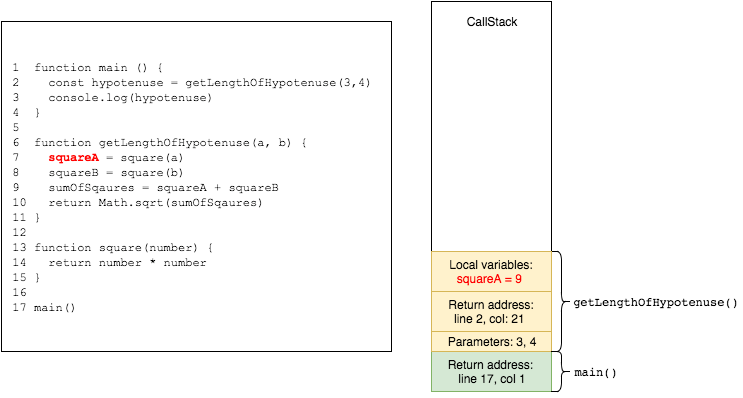
same goes for the next call to square
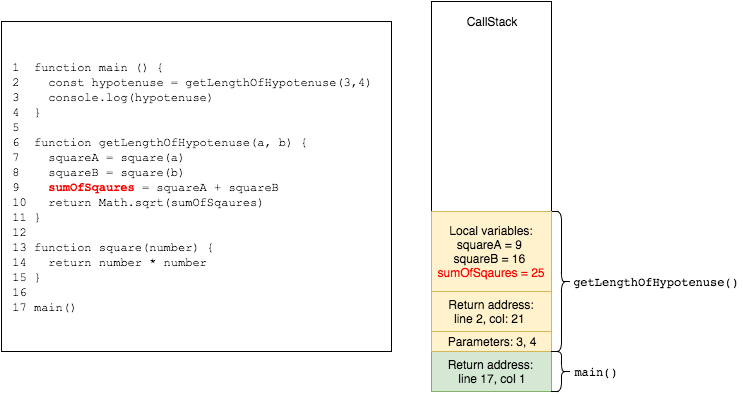
in the next line the expression squareA + squareB is evaluated
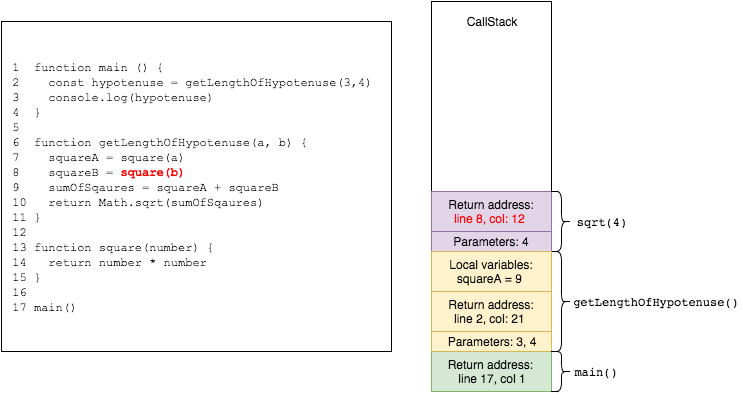
then Math.sqrt is called with sumOfSquares
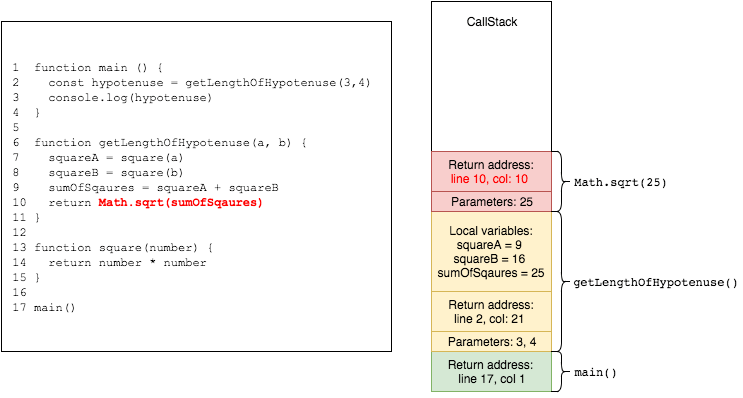
now all is left for getLengthOfHypotenuse is to return the final value of its calculation
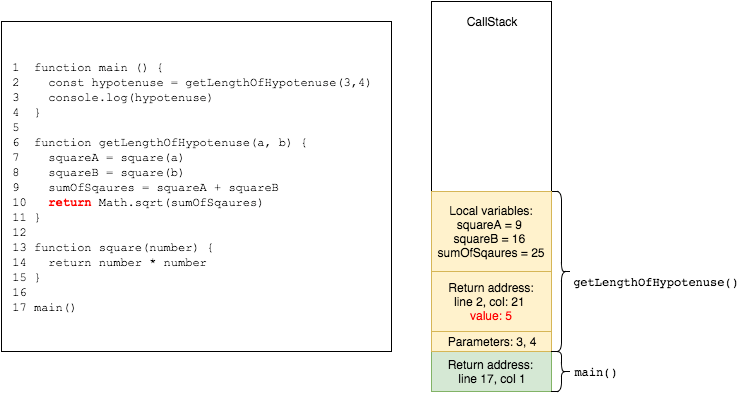
the returned value gets assigned to hypotenuse in main
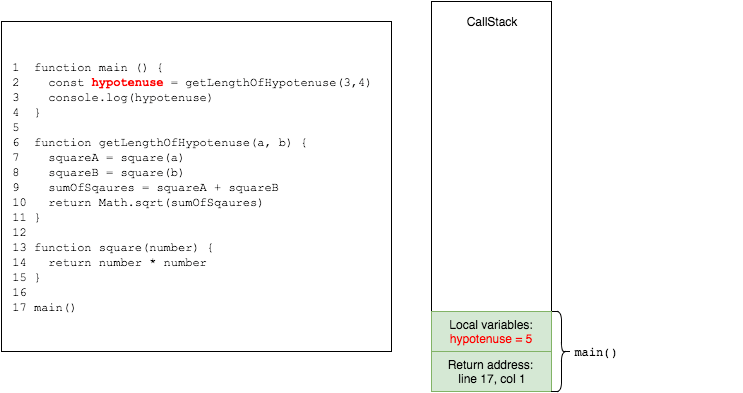
the value of hypotenuse is logged to console
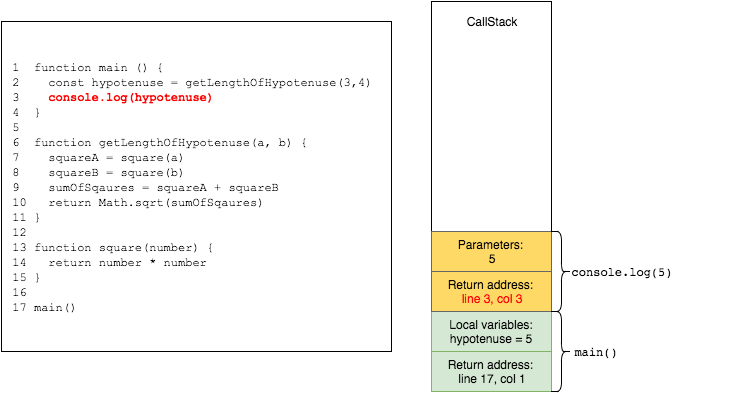
finally, main returns without any value, gets popped from the stack leaving it empty

SIDE NOTE: You saw that local variables are popped from the stack when the functions execution finishes. It happens only when you work with simple values such as numbers, strings and booleans. Values of objects, arrays and such are stored in the heap and your variable is merely a pointer to them. If you pass on this variable, you will only pass the said pointer, making these values mutable in different stack frames. When the function is popped from the stack, only the pointer to the Object gets popped with leaving the actual value in the heap. The garbage collector is the guy who takes care of freeing up space once the objects outlived their usefulness.
Enter Node.js Event Loop

No, not this loop.
If you need further assistance, you can reach us via email at info@perf.ixorasolution.com or feel free to contact us.
Thank you so much for your patience!
Happy Coding 🙂
Add a Comment